7. Internals: Developer’s Guide¶
This section is a guide for people working on the development of Data Workspaces or people who which to extend it (e.g. through their own resource types or kits).
Installation and setup for development¶
In summary:
- Install Python 3 via the Anaconda distribution.
- Make sure you have the
gitandmakeutilties on your system. - Create a virtual environment called
dwsand activate it. - Install
mypyviapip. - Clone the main
data-workspaces-pythonrepo. - Install the
dataworkpacespackage into your virtual environment. - Download and configure
rclone. - Run the tests.
Here are the details:
We recommend using Anaconda3
for development, as it can be easily installed on Mac and Linux and includes
most of the packages you will need for development and data science projects.
You will also need some basic system utilities: git and make (which may
already be installed).
Once you have Anaconda3 installed, create a virtual environment for your work:
conda create --name dws
To activate the environment:
conda activate dws
You will need the mypy
type checker, which is run as part of the tests.
It is best to install via pip to get the latest version (some older versions
may be buggy). Once you have activated your environment, mypy may be installed
as follows:
pip install mypy
Next, clone the Data Workspaces main source tree:
git clone git@github.com:data-workspaces/data-workspaces-core.git
Now, we install the data workspaces library, via pip, using an editable
mode so that our source tree changes are immediately visible:
cd data-workspaces-core
pip install --editable `pwd`
With this setup, you should not have to configure PYTHONPATH.
Next, we install rclone, a file copying utility used by the rclone resource.
You can download the latest rclone executable from http://rclone.org. Just make
sure that the executable is available in your executable path. Alternatively,
on Linux, you can install rclone via your system’s package manager. To
configure rclone, see the instructions here in the
Resource Reference.
Now, you should be ready to run the tests:
cd tests
make test
The tests will print a lot to the console. If all goes well, it should end with something like this:
----------------------------------------------------------------------
Ran 40 tests in 23.664s
OK
Overall Design¶
Here is a block diagram of the system architecture:
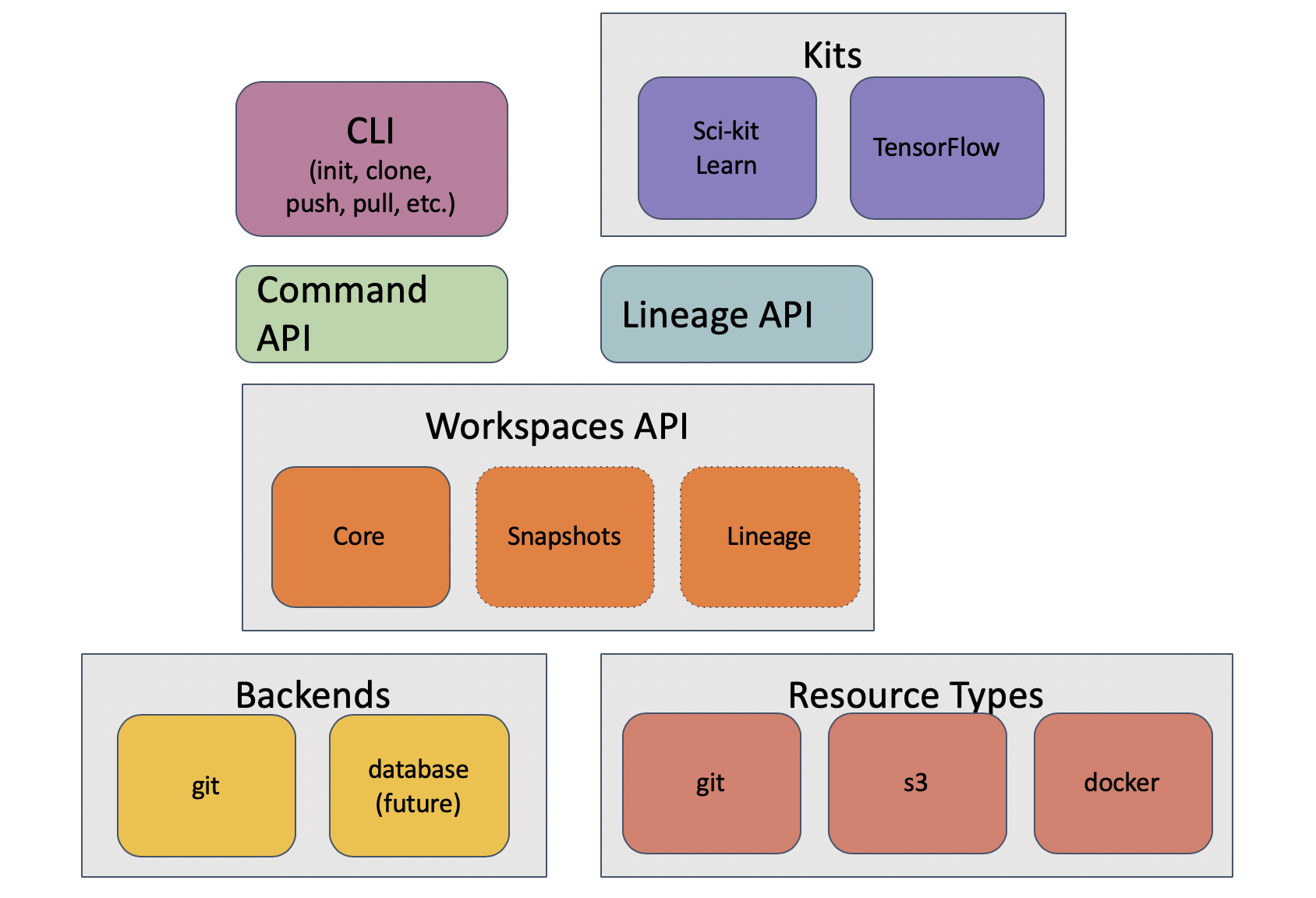
The core of the system is the Workspaces API, which is located in
dataworkspaces/workspace.py. This API provides a base Workspace classes for
the workspace and a base Resource class for resources. There are also several
mixin classes which define extensions to the basic functionality. See
Core Workspace and Resource API for details.
The Workspace class has one or more backends which implement the
storage and management of the workspace metadata. Currently, there is only
one complete backend, the git backend, which stores its metadata in
a git repository.
Independent of the workspace backend are resource types, which provide
concrete implementations of the the Resource base class. These currently include
resource types for git, git subdirectories, rclone, and local files.
Above the workspace API sits the Command API, which implements command functions
for operations like init, clone, push, pull, snapshot and restore. There is a thin layer above this for programmatic access (dataworkspaces.api) as well as a full
command line interface, implmented using the
click package
(see dataworkspaces.dws).
The Lineage API is also implemented on top of the basic workspace interface and provides a way for pipeline steps to record their inputs, outputs, and code dependencies.
Finally, kits provide integration with user-facing libraries and applications, such as Scikit-learn and Jupyter notebooks.
Code Layout¶
The code is organized as follows:
dataworkspaces/
api.py- API to run a subset of the workspace commands from Python. This is useful for building integrations.dws.py- the command line interfaceerrors.py- common exception class definitionslineage.py- the generic lineage apiworkspace.py- the core api for workspaces and resourcesbackends/- implementations of workspace backendsutils/- lower level utilities used by the upper layersresources/- implementations of the resource typescommands/- implementations of the individual dws commandsthird_party/- third-party code (e.g. git-fat)kits/- adapters to specific external technologies
Git Database Layout¶
When using the git backend, a data workspace is contained within a Git repository.
The metadata about resources,
snapshots and lineage is stored in the subdirectory .dataworkspace. The various
resources can be other subdirectories of the workspace’s repository or may be
external to the main Git repo.
The layout for the files under the .dataworkspace directory is as follows:
.dataworkspace/
config.json- overall configuration (e.g. workspace name, global params)local_params.json- local parameters (e.g. hostname); not checked into gitresources.json- lists all resources and their config parametersresource_local_params.json- configuration for resources that is local to this machine (e.g. path to the resource); not checked into gitcurrent_lineage/- contains lineage files reflecting current state of each resource; not checked into gitfile/- contains metadata for local files based resources; in particular, has the file-level hash information for snapshotssnapshots/- snapshot metadata
snapshot-<HASHCODE>.json- lists the hashes for each resource in the snapshot. The hash of this file is the hash of the overall snapshot.snapshot_history.json- metadata for the past snapshotssnapshot_lineage/- contains lineage data for past snapshots
<HASHCODE>/- directory containing the current lineage files at the time of the snapshot associated with the hashcode. Unlikecurrent_lineeage, this is checked into git.
In designing the workspace database, we try to follow the following guidelines:
- Use JSON as our file format where possible - it is human readable and editable and easy to work with from within Python.
- Local or uncommitted state is not stored in Git (we use .gitignore to keep
the files outside of the repo). Such files are initialized by
dws initanddws clone. - Avoid git merge conflicts by storing data in seperate files where possible. For example, the resources.json file should really be broken up into one file per resource, stored under a common directory (see issue #13).
- Use git’s design as an inspiration. It provides an efficient and flexible representation.
Command Design¶
The bulk of the work for each command is done by the core Workspace API
and its backends. The command fuction itself (dataworkspaces.commands.COMMAND_NAME)
performs parameter-checking, calls the associated parts of Workspace API,
and handles user interactions when needed.
Resource Design¶
Resources are orthoginal to commands and represent the collections of files to be versioned.
A resource may have one of four roles:
- Source Data Set - this should be treated read-only by the ML pipeline. Source data sets can be versioned.
- Intermediate Data - derived data created from the source data set(s) via one or more data pipeline stages.
- Results - the outputs of the machine learning / data science process.
- Code - code used to create the intermediate data and results, typically in a git repository or Docker container.
The treatment of resources may vary based on the role. We now look at resource functionality per role.
Source Data Sets¶
We want the ability to name source data sets and swap them in and out without changing other parts of the workspace. This still needs to be implemented.
Intermediate Data¶
For intermediate data, we may want to delete it from the current state of the workspace if it becomes out of date (e.g. a data source version is changed or swapped out). This still needs to be implemented.
Results¶
In general, results should be additive.
For the snapshot command, we move the results to a specific subdirectory per
snapshot. The name of this subdirectory is determined by a template that can
be changed by setting the parameter results.subdir. By default, the template
is: {DAY}/{DATE_TIME}-{USER}-{TAG}. The moving of files is accomplished via the
method results_move_current_files(rel_path, exclude) on the Resource <resources>
class. The snapshot() method of the resource is still called as usual, after
the result files have been moved.
Individual files may be excluded from being moved to a subdirectory. This is done
through a configuration command. Need to think about where this would be stored –
in the resources.json file? The files would be passed in the exclude set to
results_move_current_files.
If we run restore to revert the workspace to an
older state, we should not revert the results database. It should always
be kept at the latest version. This is done by always putting results
resources into the leave set, as if specified in the --leave option.
If the user puts a results resource in the --only set, we will error
out for now.
Integration API¶
The module dataworkspaces.api provides a simplified, high level programmatic
inferface to Data Workspaces. It is for integration with third-party tooling.
This is an API for selected Data Workspaces management functions.
-
class
dataworkspaces.api.ResourceInfo[source]¶ Named tuple representing the results from a call to
get_resource_info().-
local_path¶ Alias for field number 3
-
name¶ Alias for field number 0
-
resource_type¶ Alias for field number 2
-
role¶ Alias for field number 1
-
-
class
dataworkspaces.api.SnapshotInfo[source]¶ Named tuple represneting the results from a call to
get_snapshot_history()-
hashval¶ Alias for field number 1
-
message¶ Alias for field number 4
-
metrics¶ Alias for field number 5
-
snapshot_number¶ Alias for field number 0
Alias for field number 2
-
timestamp¶ Alias for field number 3
-
-
dataworkspaces.api.get_api_version()[source]¶ The API version is maintained independently of the overall DWS version. It should be more stable.
-
dataworkspaces.api.get_resource_info(workspace_uri_or_path: Optional[str] = None, verbose: bool = False)[source]¶ Returns a list of ResourceInfo instances, describing the resources defined for this workspace.
-
dataworkspaces.api.get_results(workspace_uri_or_path: Optional[str] = None, tag_or_hash: Optional[str] = None, resource_name: Optional[str] = None, verbose: bool = False) → Optional[Tuple[Dict[str, Any], str]][source]¶ Get a results file as a parsed json dict. If no resource or snapshot is specified, searches all the results resources for a file. If a snapshot is specified, we look in the subdirectory where the resuls have been moved. If no snapshot is specified, and we don’t find a file, we look in the most recent snapshot.
Returns a tuple with the results and the logical path (resource:/subpath) to the results. If nothing is found, returns None.
-
dataworkspaces.api.get_snapshot_history(workspace_uri_or_path: Optional[str] = None, reverse: bool = False, max_count: Optional[int] = None, verbose: bool = False) → Iterable[dataworkspaces.api.SnapshotInfo][source]¶ Get the history of snapshots, starting with the oldest first (unless :reverse: is True). Returns a list of SnapshotInfo instances, containing the snapshot number, hash, tag, timestamp, and message. If :max_count: is specified, returns at most that many snapshots.
-
dataworkspaces.api.get_version()[source]¶ Get the version string for the installed version of Data Workspaces
-
dataworkspaces.api.make_lineage_graph(output_file: str, workspace_uri_or_path: Optional[str] = None, resource_name: Optional[str] = None, tag_or_hash: Optional[str] = None, width: int = 1024, height: int = 800, verbose: bool = False) → None[source]¶ Write a lineage graph as an html/javascript page to the specified file.
-
dataworkspaces.api.make_lineage_table(workspace_uri_or_path: Optional[str] = None, tag_or_hash: Optional[str] = None, verbose: bool = False) → Iterable[Tuple[str, str, str, str, Optional[List[str]]]][source]¶ Make a table of the lineage for each resource. The columns are: ref, lineage type, details, inputs
-
dataworkspaces.api.restore(tag_or_hash: str, workspace_uri_or_path: Optional[str] = None, only: Optional[List[str]] = None, leave: Optional[List[str]] = None, verbose: bool = False) → int[source]¶ Restore to a previous snapshot, identified by either its hash or its tag (if one was specified). Parameters:
only- an optional list of resources to store. If specified all other resources will be left as-is.leave- an optional list of resource to leave as-is. Bothonlyandleaveshould not be specified together.
Returns the number of resources changed.
-
dataworkspaces.api.take_snapshot(workspace_uri_or_path: Optional[str] = None, tag: Optional[str] = None, message: str = '', verbose: bool = False) → str[source]¶ Take a snapshot of the workspace, using the tag and message, if provided. Returns the snapshot hash (which can be used to restore to this point).
Core Workspace API¶
Here is the detailed documentation for the Core Workspace API, found in
dataworkspaces.workspace.
Main definitions of the workspace abstractions
Workspace backends, like git, subclass from the Workspace base
class. Resource implementations (e.g. local files or git resource)
subclass from the Resource base class.
Optional capabilities for both workspace backends and resource backends are defined via abstract mixin classes. These classes do not inherit from the base workspace/resource classes, to avoid issues with multiple inheritance.
Complex operations involving resources use the following pattern, where COMMAND is the command and CAPABILITY is the capability needed to perform the command:
class CAPABILITYWorkspaceMixin:
...
def _COMMAND_precheck(self, resource_list:List[CAPABILITYResourceMixin]) -> None:
# Backend can override to add more checks
for r in resource_list:
r.COMMAND_precheck()
def COMMAND(sef resource_list:List[CAPAIBILITYResourceMixin]) -> None:
self._COMMAND_precheck(resource_list)
...
for r in resource_list:
r.COMMAND()
The module dataworkspaces.commands.COMMAND should look like this:
def COMMAND_command(workspace, ...):
if not isinstance(workspace, CAPABILITYWorkspaceMixin):
raise ConfigurationError("Workspace %s does not support CAPABILITY"%
workspace.name)
mixin = cast(CAPABILITYWorkspaceMixin, workspace)
... error checking ...
resource_list = ...
workspace.COMMAND(resource_list)
workspace.save("Completed command COMMAND")
Core Classes¶
-
class
dataworkspaces.workspace.Workspace(name: str, dws_version: str, batch: bool = False, verbose: bool = False)[source]¶ -
add_resource(name: str, resource_type: str, role: str, *args, **kwargs) → dataworkspaces.workspace.Resource[source]¶ Add a resource to the repository for tracking.
-
as_lineage_ws() → dataworkspaces.workspace.SnapshotWorkspaceMixin[source]¶ If this workspace supports snapshots and lineage, cast it to a SnapshotWorkspaceMixin. Otherwise, raise an NotSupportedError exception.
-
as_snapshot_ws() → dataworkspaces.workspace.SnapshotWorkspaceMixin[source]¶ If this workspace supports snapshots, cast it to a SnapshotWorkspaceMixin. Otherwise, raise an NotSupportedError exception.
-
batch= None¶ attribute: True if input from user should be avoided (bool)
-
clone_resource(name: str) → dataworkspaces.workspace.LocalStateResourceMixin[source]¶ Instantiate the resource locally. This is used in cases where the resource has local state.
-
dws_version= None¶ attribute: Version of dataworkspaces that was used to create the workspace (str)
-
get_global_param(param_name: str) → Any[source]¶ Returns the value of the global param if set, otherwise the default. If the param is not set, returns the default value. If the param is not defined throws ParamNotFoundError.
-
get_instance() → str[source]¶ Return a unique identifier for this instance of the workspace. For lineage tracking, it is assumed that only one pipeline is running at a time in an instance. If the workspace exists on a local filesystem, then it should correspond to the machine and path where the workspace resides. Typically, some combination of hostname and user are sufficient.
Uniquenes of the instance is important for things like naming the results snapshot subdirectories.
-
get_local_param(param_name: str) → Any[source]¶ Returns the value of the local param if set, otherwise the default. If the param is not set, returns the default value. If the param is not defined throws ParamNotFoundError.
-
get_names_for_resources_that_need_to_be_cloned() → Iterable[str][source]¶ Find all the resources that have local state, but no local parameters (not even an empty dict). These needed to be cloned. This is to be called during the pull() command.
-
get_names_of_resources_with_local_state() → Iterable[str][source]¶ Return an iterable of the resource names in the workspace that have local state.
-
get_resource(name: str) → dataworkspaces.workspace.Resource[source]¶ Get the associated resource from the workspace metadata.
-
get_resource_names() → Iterable[str][source]¶ Return an iterable of resource names. The names should be returned in a consistent order, specifically the order in which they were added to the workspace. This supports backwards compatilbity for operations like snapshots.
-
get_resource_role(resource_name) → str[source]¶ Get the role of a resource without having to instantiate it.
-
get_resource_type(resource_name) → str[source]¶ Get the type of a resource without having to instantiate it.
-
get_resources() → Iterable[dataworkspaces.workspace.Resource][source]¶ Iterate through all the resources
-
get_scratch_directory() → str[source]¶ Return an absolute path for the local scratch directory to be used by this workspace.
-
get_workspace_local_path_if_any() → Optional[str][source]¶ If the workspace maintains local state and has a “home” directory, return it. Otherwise, return None.
This is useful for things like providing defaults for resource local paths or providing special handling for resources enclosed in the workspace (e.g. GitRepoResource vs. GitSubdirResource)
-
map_local_path_to_resource(path: str, expecting_a_code_resource: bool = False) → dataworkspaces.utils.lineage_utils.ResourceRef[source]¶ Given a path on the local filesystem, map it to a resource and the path within the resource. Raises PathNotAResourceError if no match is found.
Note: this does not check whether the path already exists.
-
name= None¶ attribute: A short name for this workspace (str)
-
set_global_param(name: str, value: Any) → None[source]¶ Validate and set a global parameter. Setting does not necessarily take effect until save() is called
-
set_local_param(name: str, value: Any) → None[source]¶ Validate and set a local parameter. Setting does not necessarily take effect until save() is called
-
suggest_resource_name(resource_type: str, role: str, *args)[source]¶ Given the arguments passed in for creating a resource, suggest a (unique) name for the resource.
-
validate_local_path_for_resource(proposed_resource_name: str, proposed_local_path: str) → None[source]¶ When creating a resource, validate that the proposed local path is usable for the resource. By default, this checks existing resources with local state to see if they have conflicting paths and, if a local path exists for the workspace, whether there is a conflict (the entire workspace cannot be used as a resource path).
Subclasses may want to add more checks. For subclasses that do not support any local state, including in resources, they can override the base implementation and throw an exception.
-
validate_resource_name(resource_name: str, subpath: Optional[str] = None, expected_role: Optional[str] = None) → None[source]¶ Validate that the given resource name and optional subpath are valid in the current state of the workspace. Otherwise throws a ConfigurationError.
-
verbose= None¶ attribute: Print detailed logging (bool)
-
-
class
dataworkspaces.workspace.ResourceRoles[source]¶ This class defines constants for the four resource roles.
-
CODE= 'code'¶
-
INTERMEDIATE_DATA= 'intermediate-data'¶
-
RESULTS= 'results'¶
-
SOURCE_DATA_SET= 'source-data'¶
-
-
class
dataworkspaces.workspace.Resource(resource_type: str, name: str, role: str, workspace: dataworkspaces.workspace.Workspace)[source]¶ Base class for all resources
-
get_params() → Dict[str, Any][source]¶ Get the parameters that define the configuration of the resource globally.
-
name= None¶ attribute: unique name for this resource within the workspace (str)
-
resource_type= None¶ attribute: name for this resource’s type (e.g. git, local-files, etc.) (str)
-
role= None¶ Role of the resource, one of
ResourceRoles
-
validate_subpath_exists(subpath: str) → None[source]¶ Validate that the subpath is valid within this resource. Otherwise should raise a ConfigurationError.
-
workspace= None¶ attribute: The workspace that contains this resource (Workspace)
-
-
dataworkspaces.workspace.RESOURCE_ROLE_CHOICES= ['source-data', 'intermediate-data', 'code', 'results']¶ Built-in mutable sequence.
If no argument is given, the constructor creates a new empty list. The argument must be an iterable if specified.
Factory Classes and Functions¶
-
class
dataworkspaces.workspace.WorkspaceFactory[source]¶ This class collects the various ways of instantiating a workspace: creating from an existing one, initing a new one, and cloning into a new environment.
Each backend should implement a subclass and provide a singleton instance as the FACTORY member of the module.
-
static
clone_workspace(local_params: Dict[str, Any], batch: bool, verbose: bool, *args) → dataworkspaces.workspace.Workspace[source]¶ Clone an existing workspace into the local environment. Note that hostname is used as an instance identifier (TODO: make this more generic).
This only clones the workspace itself, any local state resources should be cloned separately.
If a workspace has no local state, this factory method might not do anything.
-
static
-
dataworkspaces.workspace.load_workspace(uri: str, batch: bool, verbose: bool) → dataworkspaces.workspace.Workspace[source]¶ Given a requested workspace backend, and backend-specific parameters, instantiate and return a workspace. The workspace is specified by a uri, where the backend-type is the scheme and rest is interpreted by the backend.
The backend name / scheme is used to load a backend module whose name is dataworkspaces.backends.SCHEME.
-
dataworkspaces.workspace.find_and_load_workspace(batch: bool, verbose: bool, uri_or_local_path: Optional[str] = None) → dataworkspaces.workspace.Workspace[source]¶ This tries to find the workspace and load it. There are three cases:
- If uri_or_local_path is a uri, we call load_workspace() directly
- If uri_or_local_path is specified, but not a uri, we interpret it as a local path and try to instantitate a git-backend workspace at that location in the loca filesystem.
- If uri_or_local_path is not specified, we start at the current directory and search up the directory tree until we find something that looks like a git backend workspace.
TODO: In the future, this should also look for a config file that might specify the workspace or list workspaces by name.
-
dataworkspaces.workspace.init_workspace(backend_name: str, workspace_name: str, hostname: str, batch: bool, verbose: bool, scratch_dir: str, *args, **kwargs) → dataworkspaces.workspace.Workspace[source]¶ Given a requested workspace backend, and backend-specific parameters, initialize a new workspace, then instantitate and return it.
A backend name is a module name. The module should have an init_workspace() function defined.
TODO: the hostname should be generalized as an “instance name”, but we also need backward compatibility. TODO: is this function now redundant? Compare to
load_workspace().
-
class
dataworkspaces.workspace.ResourceFactory[source]¶ Abstract factory class to be implemented for each resource type.
-
clone(params: Dict[str, Any], workspace: dataworkspaces.workspace.Workspace) → dataworkspaces.workspace.LocalStateResourceMixin[source]¶ Instantiate a local copy of the resource that came from the remote origin. We don’t yet have local params, since this resource is not yet on the local machine. If not in batch mode, this method can ask the user for any additional information needed (e.g. a local path). In batch mode, should either come up with a reasonable default or error out if not enough information is available.
-
from_command_line(role: str, name: str, workspace: dataworkspaces.workspace.Workspace, *args, **kwargs) → dataworkspaces.workspace.Resource[source]¶ Instantiate a resource object from the add command’s arguments
-
from_json(params: Dict[str, Any], local_params: Dict[str, Any], workspace: dataworkspaces.workspace.Workspace) → dataworkspaces.workspace.Resource[source]¶ Instantiate a resource object from saved params and local params
-
has_local_state() → bool[source]¶ Return true if this resource has local state and needs a clone step the first time it is used.
-
suggest_name(workspace: dataworkspaces.workspace.Workspace, role: str, *args) → str[source]¶ Given the arguments passed in to create a resource, suggest a name for the case where the user did not provide one via –name. This will be used by suggest_resource_name() to find a short, but unique name for the resource.
-
Mixins for Files and Local State¶
-
class
dataworkspaces.workspace.FileResourceMixin[source]¶ This is a mixin to be implemented by resources which provide a hierarchy of files. Examples include a git repo, local filesystem, or S3 bucket. A database would be a resource that does NOT implement this API.
-
add_results_file(data: Union[Dict[str, Any], List[Any]], rel_dest_path: str) → None[source]¶ Save JSON results data to the specified path in the resource.
-
does_subpath_exist(subpath: str, must_be_file: bool = False, must_be_directory: bool = False) → bool[source]¶ Return True the subpath is valid within this resource, False otherwise. If must_be_file is True, return True only if the subpath corresponds to content. If must_be_directory is True, return True only if the subpath corresponds to a directory.
-
read_results_file(subpath: str) → Union[Dict[str, Any], List[Any]][source]¶ Read and parse json results data from the specified path in the resource. If the path does not exist or is not a file throw a ConfigurationError.
-
results_move_current_files(rel_dest_root: str, exclude_files: Set[str], exclude_dirs_re: Pattern[AnyStr]) → None[source]¶ A snapshot is being taken, and we want to move the files in the resource to the relative subdirectory rel_dest_root. We should exclude the files in the set exclude_files and exclude any directories matching exclude_dirs_re (e.g. the directory to which the files are being moved).
-
-
class
dataworkspaces.workspace.LocalStateResourceMixin[source]¶ Mixin for the resource api for resources with local state that need to be “cloned”
-
get_local_params() → Dict[str, Any][source]¶ Get the parameters that define any local configuration of the resource (e.g. local filepaths)
-
get_local_path_if_any() → Optional[str][source]¶ If the resource has an associated local path on the system, return it. Othewise, return None. Even if it has local state, this might not be a file-based resource. Thus, the return value is an Optional string.
-
pull_precheck()[source]¶ Perform any prechecks before updating this resource from the remote origin.
-
Mixins for Synchronized and Centralized Workspaces¶
Workspace backends should inherit from one of either
SyncedWorkspaceMixin or CentralWorkspaceMixin.
-
class
dataworkspaces.workspace.SyncedWorkspaceMixin[source]¶ This mixin is for workspaces that support synchronizing with a master copy via push/pull operations.
-
publish(*args) → None[source]¶ Make a local repo available at a remote location. For example, we may make it available on GitHub, GitLab or some similar service.
-
pull_resources(resource_list: List[dataworkspaces.workspace.LocalStateResourceMixin]) → None[source]¶ Download latest updates from remote origin. By default, includes any resources that support syncing via the LocalStateResourceMixin.
Note that this does not handle the actual workspace pull or the cloning of new resources.
-
pull_workspace() → dataworkspaces.workspace.SyncedWorkspaceMixin[source]¶ Pull the workspace itself and return a new workspace object reflecting the latest state changes.
-
push(resource_list: List[dataworkspaces.workspace.LocalStateResourceMixin]) → None[source]¶ Upload updates to remote origin.
Backend subclass also needs to handle syncing of the workspace itself. If this is called with an empty set of resources, then we are just syncing the workspace. Pushing the workspace should include pushing of any new resources.
-
-
class
dataworkspaces.workspace.CentralWorkspaceMixin[source]¶ This mixin is for workspaces that have a central store and do not need synchronization of the workspace itself. They still may need to sychronize individual resources.
-
get_resources_that_need_to_be_cloned() → List[str][source]¶ Return a list of resources with local state that are not present in the local system. This is used after a pull to clone these resources.
-
Mixins for Snapshot Functionality¶
To support snapshots, the interfaces defined by
SnapshotWorkspaceMixin and SnapshotResourceMixin should
be implmented by workspace backends and resources, respectively.
SnapshotMetadata defines the metadata to be stored for each
snapshot.
-
class
dataworkspaces.workspace.SnapshotMetadata(hashval: str, tags: List[str], message: str, hostname: str, timestamp: str, relative_destination_path: str, restore_hashes: Dict[str, Optional[str]], metrics: Optional[Dict[str, Any]] = None, updated_timestamp: Optional[str] = None)[source]¶ The metadata we store for each snapshot (in addition to the manifest). relative_destination_path refers to the path used in resources that copy their current state to a subdirectory for each snapshot.
-
class
dataworkspaces.workspace.SnapshotWorkspaceMixin[source]¶ Mixin class for workspaces that support snapshots and restores.
-
delete_snapshot(hash_val: str, include_resources=False) → None[source]¶ Given a snapshot hash, delete the entry from the workspace’s metadata. If include_resources is True, then delete any data from the associated resources (e.g. snapshot subdirectories).
-
get_lineage_store() → dataworkspaces.utils.lineage_utils.LineageStore[source]¶ Return the store for lineage data. If this workspace backend does not support lineage for some reason, the call should raise a ConfigurationError.
-
get_most_recent_snapshot() → Optional[dataworkspaces.workspace.SnapshotMetadata][source]¶ Helper function to return the metadata for the most recent snapshot (by timestamp). Returns None if no snapshot found
-
get_next_snapshot_number() → int[source]¶ Return a number that can be used for this snapshot. For a given local copy of thw workspace, it is guaranteed to be unique and increasing. It is not guarenteed to be globally unique (need to combine with hostname to get that).
-
get_snapshot_by_partial_hash(partial_hash: str) → dataworkspaces.workspace.SnapshotMetadata[source]¶ Given a partial hash for the snapshot, find the snapshot whose hash starts with this prefix and return the metadata asssociated with the snapshot.
-
get_snapshot_by_tag(tag: str) → dataworkspaces.workspace.SnapshotMetadata[source]¶ Given a tag, return the asssociated snapshot metadata. This lookup could be slower ,if a reverse index is not kept.
-
get_snapshot_by_tag_or_hash(tag_or_hash: str) → dataworkspaces.workspace.SnapshotMetadata[source]¶ Given a string that is either a tag or a (partial)hash corresponding to a snapshot, return the associated resrouce metadata. Throws a ConfigurationError if no entry is found.
-
get_snapshot_manifest(hash_val: str) → Dict[str, Any][source]¶ Returns the snapshot manifest for the given hash as a parsed JSON structure. The top-level dict maps resource names resource parameters.
-
get_snapshot_metadata(hash_val: str) → dataworkspaces.workspace.SnapshotMetadata[source]¶ Given the full hash of a snapshot, return the metadata. This lookup should be quick.
-
list_snapshots(reverse: bool = True, max_count: Optional[int] = None) → Iterable[dataworkspaces.workspace.SnapshotMetadata][source]¶ Returns an iterable of snapshot metadata, sorted by timestamp ascending (or descending if reverse is True). If max_count is specified, return at most that many snaphsots.
-
remove_tag_from_snapshot(hash_val: str, tag: str) → None[source]¶ Remove the specified tag from the specified snapshot. Throw an InternalError if either the snapshot or the tag do not exist.
-
restore(snapshot_hash: str, restore_hashes: Dict[str, str], restore_resources: List[SnapshotResourceMixin]) → None[source]¶ Restore the specified resources to the specified hashes. The list should have been previously filtered to include only those with valid (not None) restore hashes.
-
save_snapshot_metadata_and_manifest(metadata: dataworkspaces.workspace.SnapshotMetadata, manifest: bytes) → None[source]¶ Save the snapshot metadata and manifest using the hash in metadata.hashval.
-
snapshot(tag: Optional[str] = None, message: str = '') → Tuple[dataworkspaces.workspace.SnapshotMetadata, bytes][source]¶ Take snapshot of the resources in the workspace, and metadata for the snapshot and a manifest in the workspace. We assume that the tag does not already exist (checks can be made in the command before calling this method).
We also copy the lineage data if the workspace supports lineage.
Returns the snapshot metadata and the (binary) snapshot hash. These should be saved into the workspace by the caller (i.e. the snapshot command). We don’t do that here, as futher interactions with the user may be needed. In particular, if the hash is identical to a previous hash, we ask the user if they want to overwrite.
-
-
class
dataworkspaces.workspace.SnapshotResourceMixin[source]¶ Mixin for the resource api for resources that can take snapshots.
-
delete_snapshot(workspace_snapshot_hash: str, resource_restore_hash: str, relative_path: str) → None[source]¶ Delete any state associated with the snapshot, including any files under relative_path
-
restore_precheck(restore_hashval: str) → None[source]¶ Run any prechecks before restoring to the specified hash value (aka certificate). This should throw a ConfigurationError if the restore would fail for some reason.
-
snapshot() → Tuple[Optional[str], Optional[str]][source]¶ Take the actual snapshot of the resource and return a tuple of two hash values, the first for comparison, and the second for restoring. The comparison hash value is the one we save in the snapshot manifest. The restore hash value is saved in the snapshot metadata. In many cases both hashes are the same. If the resource does not support restores, it can return None for the second hash. This will cause attempted restores involving this resource to error out.
-